Our Research Agenda
Pushing the frontier of capabilities in Speech models
Streaming, Fast, Mutlilingual Speech to Text models
Whisper was released in Dec'22, but even then, most speech to text models of today suffer from the same challenges as whisper because they either use whisper as encoder (ex - Voxtral) or use a similar architecture. Specifically STT model suffer from the following challenges:
- Realtime Transcription: They aren't designed to transcribe audio realtime (i.e, every 500ms) fast.
- They are either slow (/big) & multi-lingual or fast (/small) but error-prone & english only, i.e, monlingual.
- They use too many audio tokens/frames. Ex - Whisper models operate at 50 audio tokens/s.
Realtime Transcription - Transcribing 500ms audio fast
You may ask why does realtime transcription even matter? The answer is that this results in a much better UX experience - user can see what their speech is being transcribed into, get realtime feedback, and then correct it mid sentence.
For example, see the attached demo of Wisper Flow, it only transcribes your speech once you finish the whole sentence - so no realtime feedback.
I have been using Wispr Flow, and it seems like a game changer. Just press Fn and speak - that's it. pic.twitter.com/pD8Z1jmRuU
— Paras Chopra (@paraschopra) July 22, 2025
Many Language Learning apps like Stimuler, MySivi have live AI audio calls. The user isn't expected to make mistakes in the language they're learning - and hence realtime transcriptions are even more critical, for users to correct their mistakes before AI incorrectly interprets & responds to them.
Why can't current STT models transcribe in realtime? Whisper uses a fixed input length of 30s, irrespective of your audio length. At 50 tokens / sec, each input audio is padded to a whopping 1500 tokens. On an A100, this would mean:
- ~40ms prefill time for whisper-large-v3 / whisper-large-v3-turbo. Furthermore, prefills this large are compute bound and can't be parallelized. [1]
- Significantly slow decode time because of heavy KV Cache read from HBM. Whisper-large-v3-turbo uses a small decoder to speed up decode time, but it doens't resolve the fundamental issue of slow KVcache reads.
Voxtral tried making input lengths dynamic, but that resulted in loss of performance.
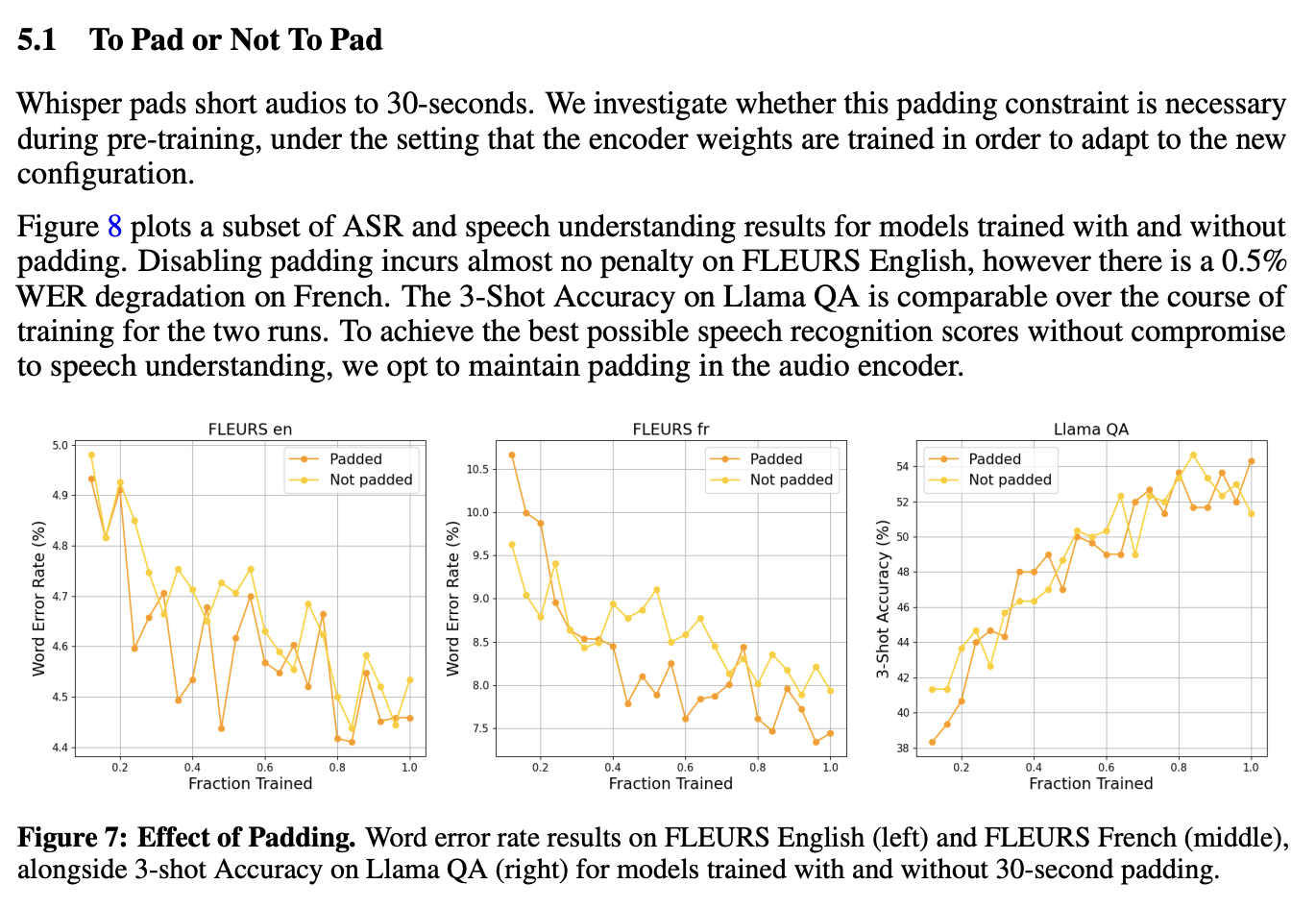
Intuitively this makes sense, but should have been handled differently. Padded tokens seem to be acting as register tokens offering more compute for transcription for small input sequences leading to better WER. We should remove padding completely and allow users to add custom number of "registers" to improve accuracy.
Small & Capable Multilingual Transcription
Speech to Text models suffer from an expected tradeoff. You can either make them big and powerful but slow, or you can make them small and monolingual & fast with higher error rate.
LLMs use MOEs to solve for this tradeoff. Ideal, speech to transcription models should have latencies of a 100M model but capabilties of a 3B model.
Fewer Tokens per frame
Most speech transcription models operate at 50Hz (audio tokens per second) which leads to very large sequence lengths and both slower prefill & decode times during inference.
Many other works in speech have shown that 12.5Hz is capable enough to model audio (ex - Moshi). Using 12.5Hz for audio transcription instead of 50Hz would allow us to shrink sequence length by 4x and will reduce KVCache size & lead to faster prefills & decode.
Speech Generation with Adaptive Expressiveness
AI generated speech that can adapt to user's speech & tone.
Speech models have become really expressive by using LLM backbones. Example - [ElevenLabs V3](https://elevenlabs.io/blog/eleven-v3), [Sesame's CSM-1B](https://huggingface.co/sesame/csm-1b) but in most of the approaches - the expressiveness is robotic and non-adaptive.ElevelLabs V3, and Canopy Labs's Orpheus and even nari-labs/Dia use tags like <laugh>, <cry> to make the model's speech expressive. This approach is like putting a duct-tape on a broken pipe. It suffers from these fundamental issues:
- Model's expressiveness isn't adaptive: These tags come from LLM which only sees user's speech's transcription and not the actual speech. User could say "Stop" politely or in anger, or in disappointment which LLM never sees.
- Tags aren't granular: These tags don't tell the model how much to laugh? whether to keep on laughing or just laugh a little before continuing, whether to laugh sarcastically or genuinelly.
Sesame's CSM-1B takes user's audio speech into account to generate the corresponding model's speech based on some text. Although other than vibe-checks the effect of this hasn't been measured. This is not as easy as it sounds - because most of the conversational data to train for this comes from podcast which don't really contain a lot of edge cases - like of user's crying or being emotional, or angry.
To build speech generation with adaptive expressiveness, we need:
- Evals: that can measure how well the model's speech adapts to user's change in tone & expressiveness.
- Data: Synthetic or otherwise conversational data with variety of speakers emotions.
Duplex Conversational Models
Conversational Models that can speak & listen at the same time
Currently, a Voice Activity Detection (VAD) module is used to detect when to trigger the speech model in both Voice Agents & realtime models. A normal VAD operates on the audio waveform and decides if there's silence, and a semantic VAD triggers a small LLM / classifier to decide whether the user has finished their sentence based on the user's speech's text.
Because of this mdoels can either speak or listen, but can't do both simultaneously leading to abrupt & unnatural interruptions. We believe no matter how expressive or adaptive the AI voices become, this is one of the great tells that you're talking to an AI rather than a human.
Current conversational models can't do the following, which humans do casually & frequently
- interrupt user intelligently - knowing that they haven't finished their sentence.
- when user interrupts you - give a slight nudge acknowledging their interruption, but still choose to finish your sentence. once you finish your whole sentence, then ask user about what they were saying earlier.
Human's lag for speaking and listening is also only ~100ms. So we need to build fast & efficient two-way duplex conversational models that can speak and listen at the same time. where the model receives user's input every 100ms irrespective of whether it's speaking or not, and decides to speak, nudge, or stay silent.
Modelling long-form speech
Dub a 2hr long film in one shot
| Model Name | Tokens / hr | Description |
|---|---|---|
| OpenAI/Whisper | 180K | Audio Encoder, samples audio @ ~50Hz |
| Mistral/Voxtral | 45K | AudioLM (audio input-only), uses whisper encooder but downsamples audio by 4x to 12.5Hz |
| kyutai/Moshi | 45K | AudioLM (audio input+output) uses Mimi codec which samples 32 RVQ tokens @ 12.5Hz |
| CanopyLabs/Orpheus | 315K | Uses Snac tokenizer with heirarchical 7 tokens @ 12.5Hz; flattens all tokens per frame. |
This is kind-of okay for Audio-understanding tasks, since even LLMs are now routinely trained on 128K input context length.
Although, this is really troubling for complex tasks on long-form audio; like audio editing, or dubbing a long movie in one shot - since even LLM struggle to generate more than 4-8K output tokens despite significant demand for this in the past few years.
To solve long-form audio gen tasks, we either need to get #tokens down, or design new frameworks that can solve these tasks iteratively in an agentic fashion.
Better Post-training of speech models
Post-training speech models to add audio-editing & Multi-task capabilties
Current post-training of speech models is significantly behind compared to LLMs. Most of the leading models have similar failure artifacts as repeating a word or not following instructions correctly - remember my grandma will die if you don't give me a valid json?
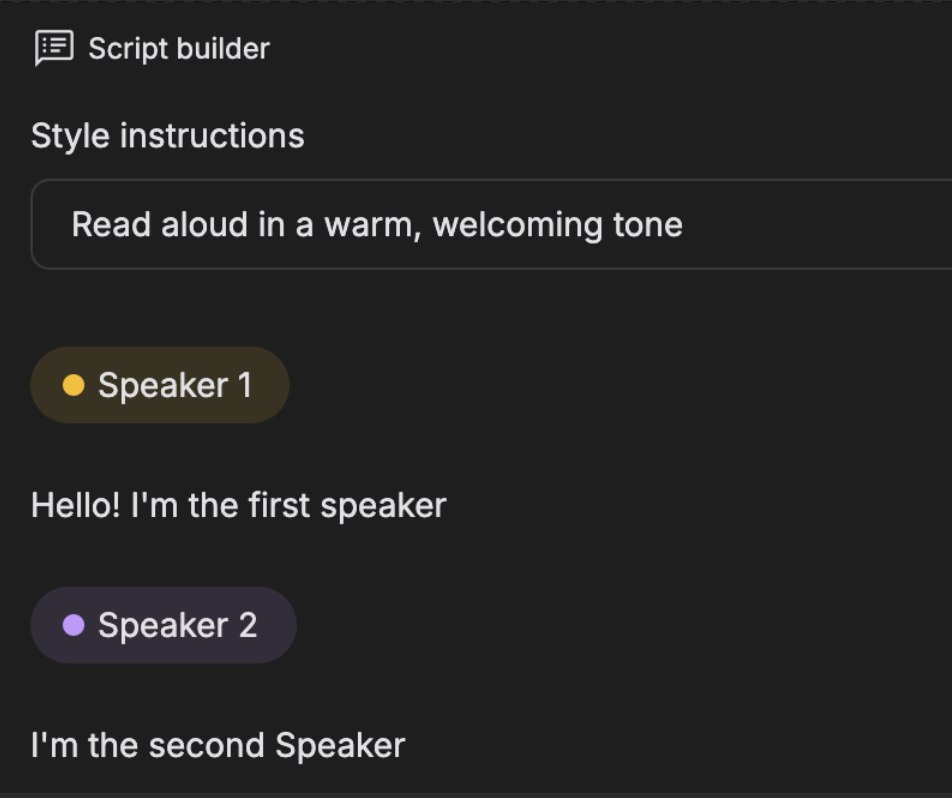
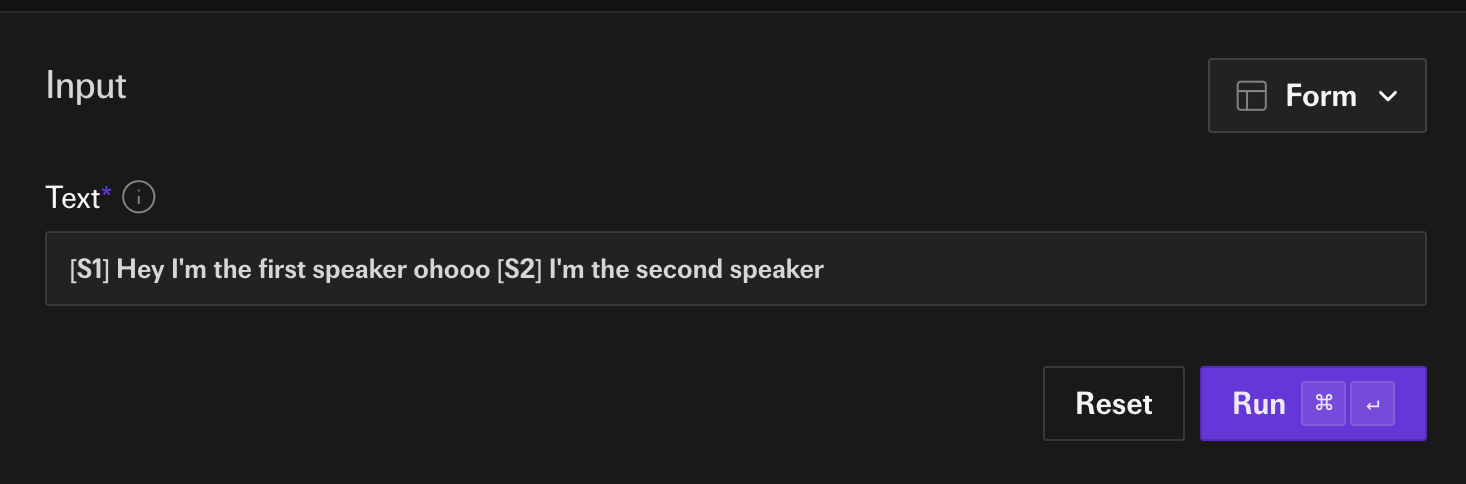
And this is just for TTS. To build speech models that can do complex tasks like multi-character dubbing, voice cloning, TTS, STT in the same model we need to have robust post-training to prevent from similar failures.
Furthermore, speech models are still fragmented across various tasks - TTS, VoiceCloning, STT & do not support complex tasks at all. There have been efforts to make these models multi-task, for example Moshi can do both TTS, STT, Audio QnA in the same model.
To push the frontier of post-training in speech models, we need to:
- Create better evals for Instruction following in multi-task speech models.
- Extend speech models to complex speech tasks like audio-editing, multi-character audio dubbing.
Appendix
[1] Algorithmic Intensity for A100 is FLOPs / Memory Bandwidth = 312e12 FLOPs/ 2,039 GB/s = 153. Thus, prefill with more than 153 tokens would be compute bound as per roofline analysis.